· David Lecomte · Performance web · 7 min de lecture
Performance web : mesurez avant d'optimiser
40 % des visiteurs quittent un site après 3 secondes d'attente. Pourtant, la plupart des projets mettent de côté l'optimisation ou le font à l'aveugle. Voici pourquoi le monitoring doit précéder toute optimisation - et comment le mettre en place concrètement.
Chaque seconde compte. Littéralement.
Les chiffres parlent d’eux-mêmes : 40 % des utilisateurs quittent un site après 3 secondes de chargement. Au-delà de 5 secondes, le taux de rebond peut doubler par rapport à un site rapide. Et pour les équipes produit ou e-commerce, le ratio le plus douloureux reste celui-ci : chaque seconde supplémentaire fait baisser le taux de conversion d’environ 7 % (OpenStudio, 2025).
Sur mobile, la barre est encore plus haute. 72 % des utilisateurs français citent la lenteur comme première cause d’abandon d’un site ou d’une application (Amplitude/Opinium, 2025).
Ces statistiques ne sont pas nouvelles. Ce qui change, c’est que la performance est désormais mesurée, attendue, et comparée en permanence par vos utilisateurs.
Le piège du “ça marche”
Un projet peut être techniquement solide - architecture propre, tests au vert, fonctionnalités livrées dans les délais - et pourtant souffrir de performances catastrophiques en production.
Pourquoi ? Parce que la performance n’est pas une fonctionnalité qu’on ajoute, c’est une propriété qu’on mesure et qu’on maintient dans le temps.
Quelques symptômes classiques d’un projet qui n’a pas intégré la performance comme critère :
- Des requêtes SQL non indexées qui passent inaperçues en développement (quelques milliers de lignes) mais deviennent des goulots d’étranglement en production (millions de lignes).
- Des appels d’API synchrones en cascade qui multiplient les temps de réponse.
- Un rendu serveur qui charge des données inutiles à chaque requête, faute de cache.
- Des assets non optimisés (images en PNG 2 Mo, JS non minifié) qui plombent le Time to First Byte et le LCP (le Largest Contentful Paint est une mesure de performance qui évalue le temps de chargement du contenu principal d’une page web).
Et le problème numéro un : sans instrumentation, on ne sait pas où est le vrai problème. On optimise au feeling, on déploie des changements parfois inutiles, et on rate les vrais coupables.
Mesurer d’abord, optimiser ensuite
Le principe semble évident. Il est pourtant rarement appliqué rigoureusement.
Voici la méthodologie que j’applique sur les projets que j’accompagne :
On ne touche pas au code avant d’avoir une baseline de mesure.
Concrètement, ça veut dire : mettre en place les outils de monitoring avant de commencer à optimiser, pour comparer l’avant et l’après avec des données objectives, pas des impressions.
Cette approche se décline en trois niveaux complémentaires : l’application, le serveur, et les APIs.
Niveau 1 - Monitoring applicatif
Symfony Profiler et Blackfire
Si votre stack backend est Symfony, le Symfony Profiler est votre premier allié. Il permet d’analyser, requête par requête :
- Le nombre et la durée des requêtes SQL (et de détecter les problèmes N+1)
- Le temps passé dans chaque template Twig
- La consommation mémoire
- Les événements Symfony dispatchés
C’est l’outil idéal en développement et en staging. Pour aller plus loin en production, Blackfire (de Sensio/Symfony) permet de profiler de manière non intrusive, avec des assertions automatiques sur les performances via des “builds” CI.
# Installer Blackfire Agent + CLI
# Puis profiler une requête HTTP
blackfire curl https://mon-app.fr/api/produitsLe résultat : un graphe de call stack détaillé, avec les fonctions les plus coûteuses clairement identifiées.
New Relic en production
Pour un monitoring continu en production, New Relic (ou ses alternatives open source comme Glitchtip + OpenTelemetry) offre une vision temps réel de la santé applicative :
- APM (Application Performance Monitoring) : temps de réponse moyen par transaction, percentiles p95/p99
- Distributed tracing : suivi d’une requête de bout en bout à travers les services
- Alertes : notification dès qu’une transaction dépasse un seuil défini
Ce que le Profiler ne fait pas, New Relic le fait : persister les données dans le temps. On peut comparer les performances d’hier à celles d’aujourd’hui, et corréler une dégradation avec un déploiement spécifique.
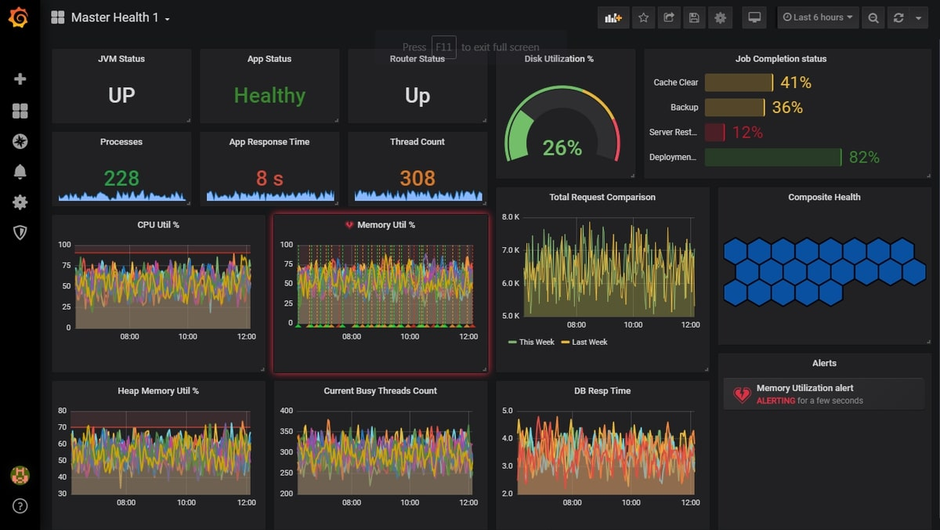
Niveau 2 - Monitoring infrastructure
L’application peut être parfaitement optimisée et pourtant souffrir de problèmes d’infrastructure. CPU saturé, mémoire proche du swap, réseau congestionné : ces problèmes sont invisibles au niveau applicatif.
Prometheus + Grafana
La combinaison Prometheus + Grafana est aujourd’hui le standard de facto pour le monitoring serveur dans les environnements modernes.
- Prometheus collecte les métriques exposées par vos services (via exporters) : node_exporter pour le serveur, mysqld_exporter pour MySQL, php-fpm_exporter pour PHP-FPM, etc.
- Grafana permet de visualiser ces métriques sous forme de dashboards, et de configurer des alertes (PagerDuty, Slack, email).
Quelques métriques critiques à surveiller :
| Métrique | Seuil d’alerte suggéré |
|---|---|
| CPU usage | > 80 % sur 5 min |
| Memory usage | > 85 % |
| PHP-FPM active workers | > 80 % du pool |
| MySQL slow queries | > 0 requête/s > 2s |
| Disk I/O wait | > 20 % |
Un dashboard Grafana bien configuré vous permet de détecter une dégradation avant que vos utilisateurs ne la signalent - et c’est souvent là que ça fait toute la différence.
Niveau 3 - Monitoring API
Quand une application expose ou consomme des APIs, la performance de ces échanges est souvent sous-estimée.
Gravitee.io - API Gateway
Gravitee.io est une API Gateway open source qui se place en frontal de vos APIs pour offrir :
- Analytics détaillées : latence par endpoint, volume de requêtes, taux d’erreur
- Rate limiting et quotas : protection contre les abus et les pics de charge non maîtrisés
- Cache : mise en cache des réponses d’API côté gateway, sans modifier le backend
- Alertes : seuils de latence, SLA par consommateur
Concrètement, Gravitee.io permet de répondre à des questions simples mais souvent sans réponse : Quel endpoint est le plus lent ? Quel consommateur génère le plus de trafic ? Où se situent les timeouts ?
Sans API Gateway, ces informations sont soit noyées dans des logs difficiles à exploiter, soit tout simplement absentes.
Les optimisations ciblées
Une fois le monitoring en place et les goulots d’étranglement identifiés, on peut passer aux optimisations avec des données concrètes pour valider l’impact de chaque changement.
Base de données
C’est souvent là que se cachent les gains les plus rapides et les plus significatifs :
- Indexation : vérifier que les colonnes utilisées dans les
WHERE,JOINetORDER BYsont indexées. UnEXPLAINouEXPLAIN ANALYZE(PostgreSQL) révèle les full scans. - Optimisation des requêtes : éliminer les requêtes N+1 (utiliser
JOINou eager loading via Doctrine), réduire lesSELECT *, paginer les résultats. - Mise en cache : pour les données peu volatiles, un cache applicatif (Redis, Memcached) ou un cache de second niveau Doctrine peut réduire drastiquement la charge DB.
Conception et développement
- Lazy loading : ne charger les ressources (images, modules JS) que lorsqu’elles entrent dans le viewport.
- Formats modernes : remplacer JPEG/PNG par WebP ou AVIF pour les images, avec un gain de 30 à 50 % sur le poids des assets à qualité équivalente.
- APIs paginées : ne jamais retourner des collections entières sans limite. Implémenter la pagination côté serveur (cursor-based pour les grandes tables).
- Configuration PHP : activer OPcache (met en cache l’opcode PHP compilé), et configurer correctement les pools PHP-FPM selon les ressources disponibles. Il est aussi possible de migrer vers FrankenPHP qui offre d’excellentes performances.
Infrastructure
- CDN : externaliser la distribution des assets statiques (images, CSS, JS) sur un CDN (Cloudflare, BunnyCDN). Le TTFB perçu chute immédiatement pour les visiteurs éloignés géographiquement.
- Cache serveur : Varnish en reverse proxy devant votre serveur applicatif peut servir des milliers de requêtes identiques sans jamais toucher PHP ou la base de données.
- Scalabilité horizontale : mise en place d’un load balancer pour distribuer la charge entre plusieurs instances applicatives lors des pics.
- Scalabilité verticale : ajustement des ressources allouées (RAM, CPU) au plus juste selon les métriques - ni sous-dimensionné, ni sur-provisionné.
La performance comme culture d’équipe
La performance n’est pas le travail d’une seule personne ni d’une seule phase du projet. C’est quelque chose qui s’intègre dans les habitudes de l’équipe :
- Définir des budgets de performance dès la phase de conception (ex : LCP < 2,5s, TTFB < 200ms)
- Intégrer des tests de performance automatisés dans la CI/CD (Lighthouse CI, k6, Blackfire)
- Faire des revues de performance régulières, au même titre que les revues de code
- Traiter une régression de performance avec la même urgence qu’un bug fonctionnel
En résumé
La performance web est un accélérateur de croissance, pas un bonus technique réservé aux grandes entreprises. Et la clé, c’est de ne jamais optimiser à l’aveugle.
La méthode en quatre étapes :
- Instrumenter - monitoring applicatif (Symfony Profiler, New Relic), serveur (Prometheus + Grafana), APIs (Gravitee.io)
- Mesurer - établir une baseline, identifier les vrais goulots d’étranglement
- Optimiser - cibler les changements à fort impact : base de données, assets, cache, infrastructure
- Valider - mesurer l’impact de chaque changement avec les mêmes outils
Sans les étapes 1 et 2, l’étape 3 est un pari. Avec elles, c’est une certitude.
Vous travaillez sur une application dont les performances se dégradent, ou vous voulez simplement savoir où vous en êtes ? Prenons contact - c’est exactement le type de mission sur lequel j’interviens.